ImageTransform vs Concatenate execution time







Hi all,
I was testing what is the fastest way to stack 2d waves. I did a comparison between "ImageTrasnform stackImages" and "Concatenate".
I used the following code.
Function MakeTheWaves(variable nn)
variable i
for(i = 0;i < nn; i++)
Make/O/N=(4096,4096) $("wname_" + num2str(i))
endfor
return 0
End
Function MakeTheWaveRefs(variable nn)
variable i
Make/O/N=(nn)/WAVE mxpwaveRef
for(i = 0;i < nn; i++)
mxpwaveRef[i] = $("wname_" + num2str(i))
endfor
return 0
End
Function [variable tN0, variable tP0, variable tN1, variable tP1] timerFunction(variable nn)
MakeTheWaves(nn)
MakeTheWaveRefs(nn)
WAVE/T mxpwaveRef
variable tm00=stopmstimer(-2)
ImageTransform/NP=(nn) stackImages $"wname_0"
variable tm01=stopmstimer(-2)
variable tm10=stopmstimer(-2)
Concatenate/O/NP=2 {mxpwaveRef}, M_Concatenate
variable tm11=stopmstimer(-2)
tN0 = (tm01-tm00)/1e6
tN1 = (tm11-tm10)/1e6
// Now all stacks are pre-allocated, redo the operations
tm00=stopmstimer(-2)
ImageTransform/NP=(nn) stackImages $"wname_0"
tm01=stopmstimer(-2)
tm10=stopmstimer(-2)
Concatenate/O/NP=2 {mxpwaveRef}, M_Concatenate
tm11=stopmstimer(-2)
tP0 = (tm01-tm00)/1e6
tP1 = (tm11-tm10)/1e6
KillWaves/A/Z
return [tN0, tP0, tN1, tP1] // 0 = ImageTransform, 1 = Concatenate
End
Function RunTheTest(int startN, int stopN, int stepN) // Entry point
variable nn, i, tN0, tP0, tN1, tP1
string dataFolderName = "TestResults_" + num2str(startN) + "_" + num2str(stopN) + "_" + num2str(stepN)
NewDataFolder/O $dataFolderName
DFREF dfr = $dataFolderName
int sizeN = (stopN - startN)/stepN + 1
Make/N=(sizeN) dfr:results_CN /WAVE=wcn
Make/N=(sizeN) dfr:results_IT /WAVE=wit
Make/N=(sizeN) dfr:results_CN_Pre /WAVE=wcnP
Make/N=(sizeN) dfr:results_IT_Pre /WAVE=witP
SetScale/P x, startN, stepN, "Nr. Images", wcn, wcnP, wit, witP
for(nn = startN; nn < stopN + 1; nn += stepN)
[tN0, tP0, tN1, tP1] = timerFunction(nn)
wcn[i] = tN1
wit[i] = tN0
wcnP[i] = tP1
witP[i] = tP0
i++
endfor
End
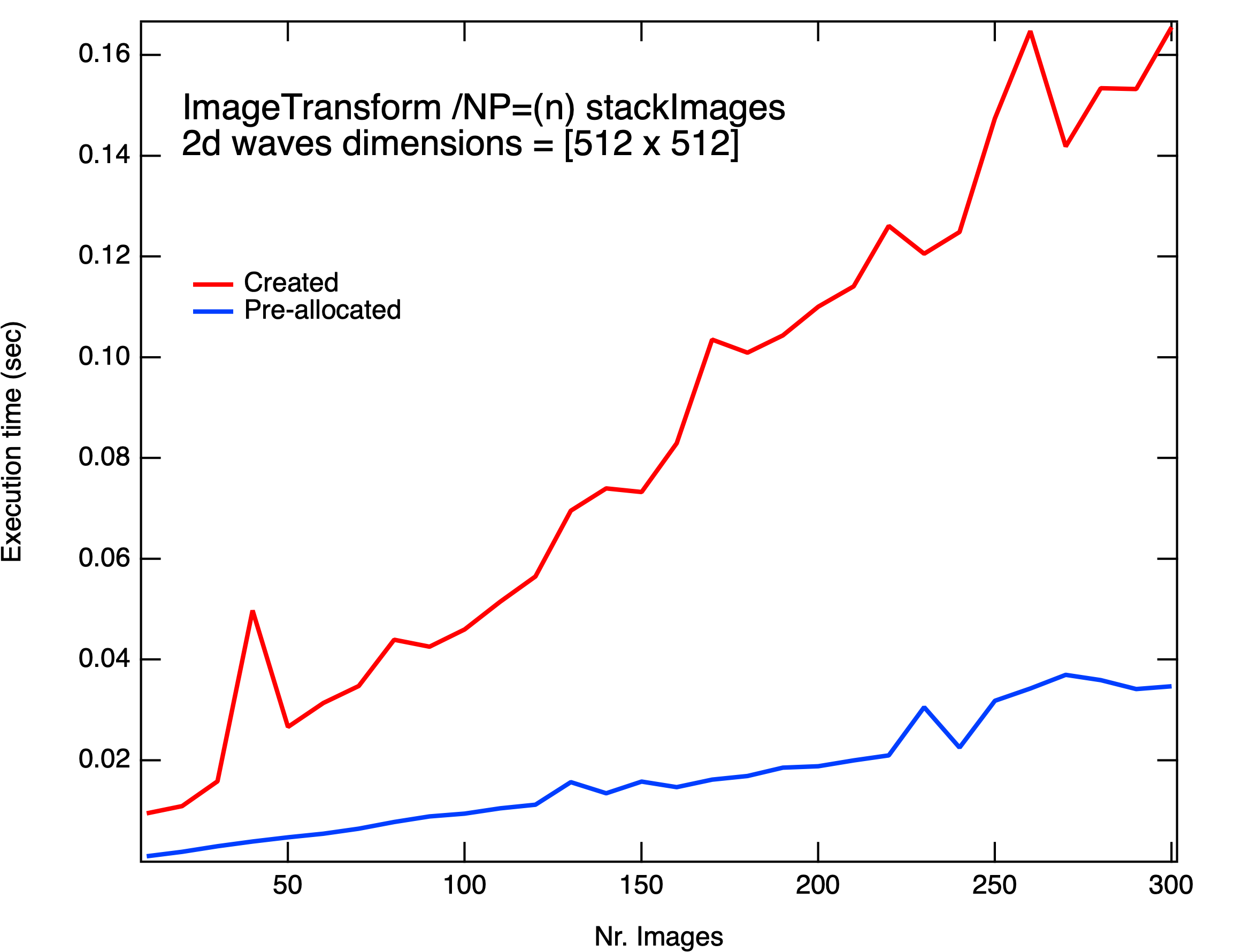
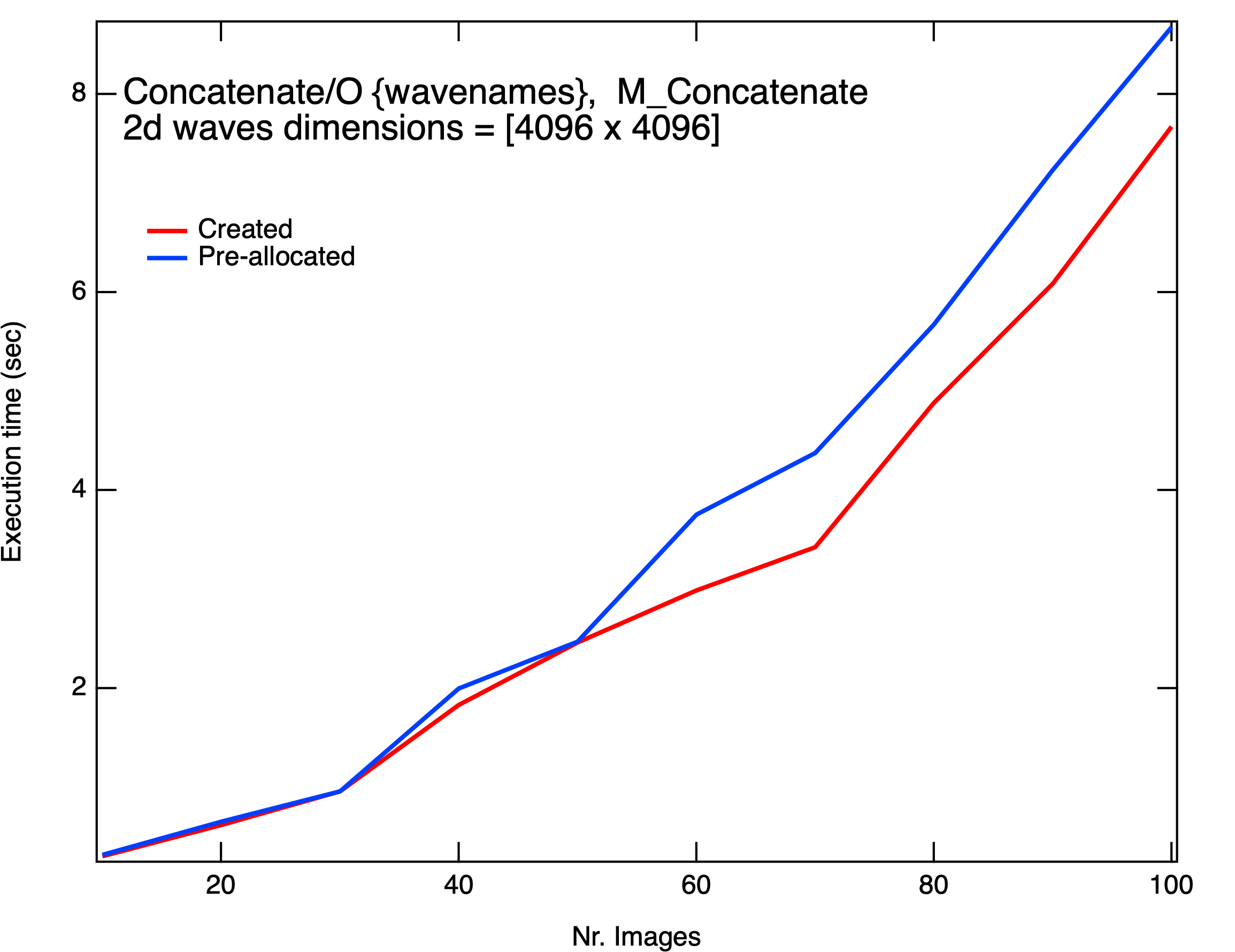
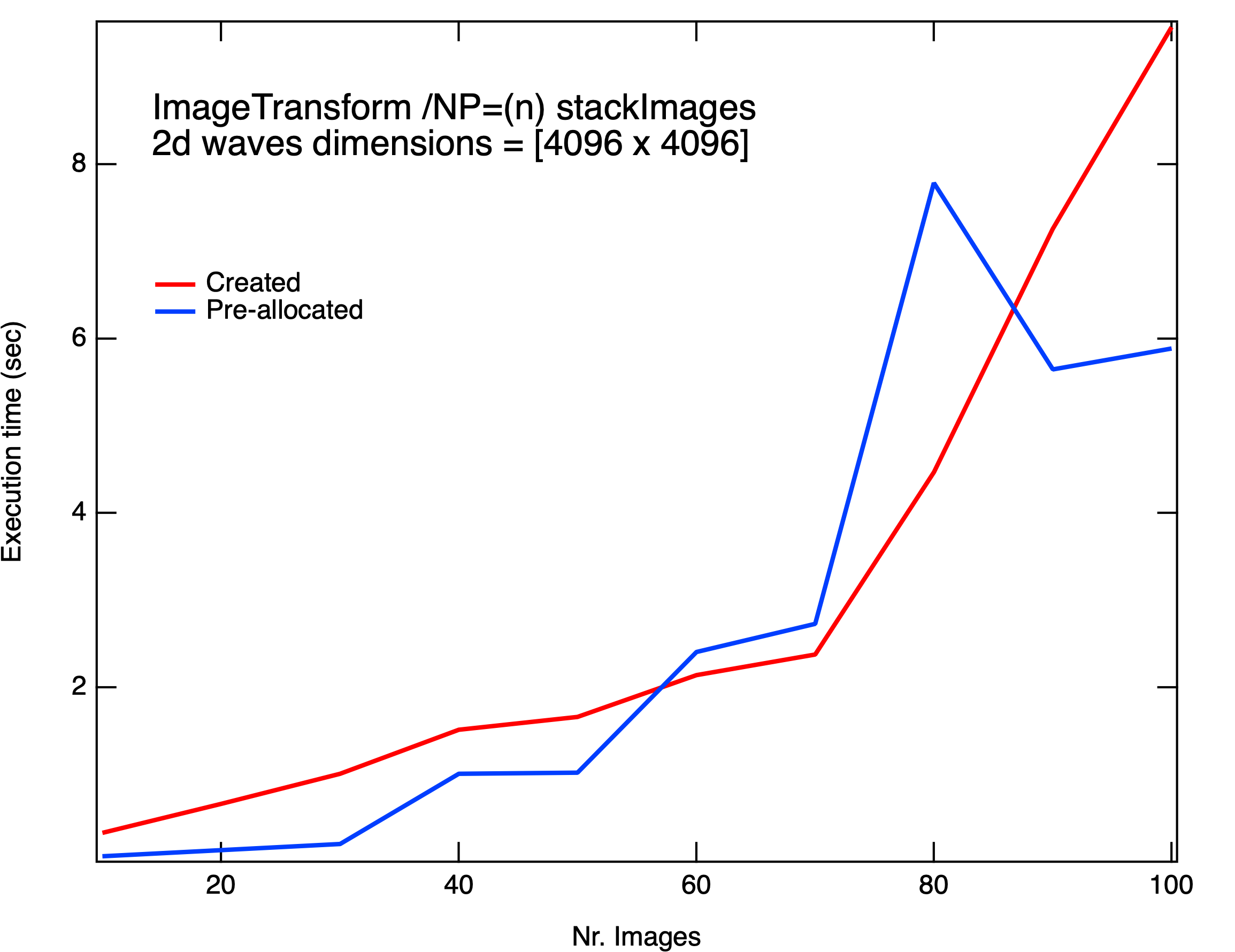
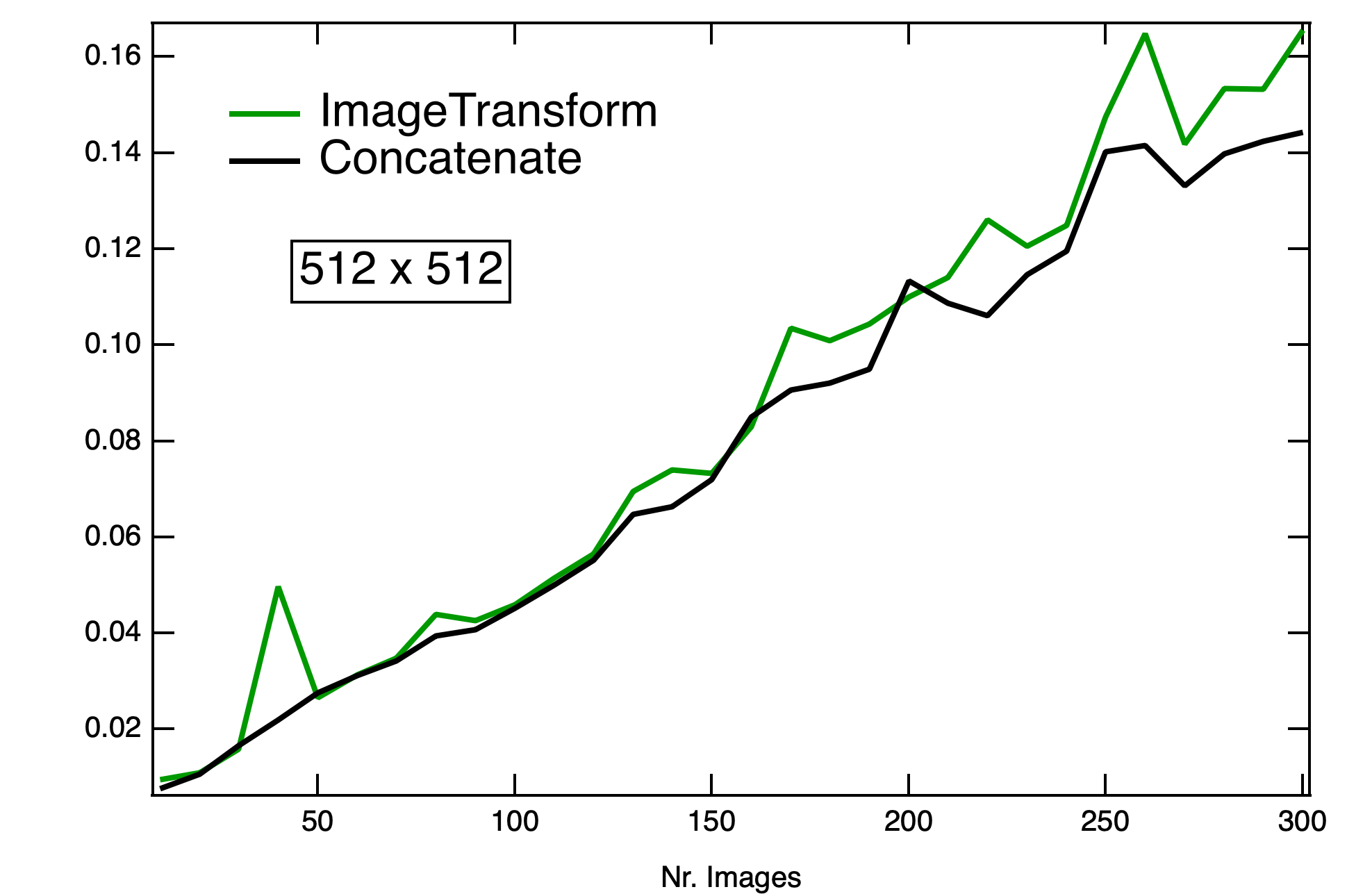
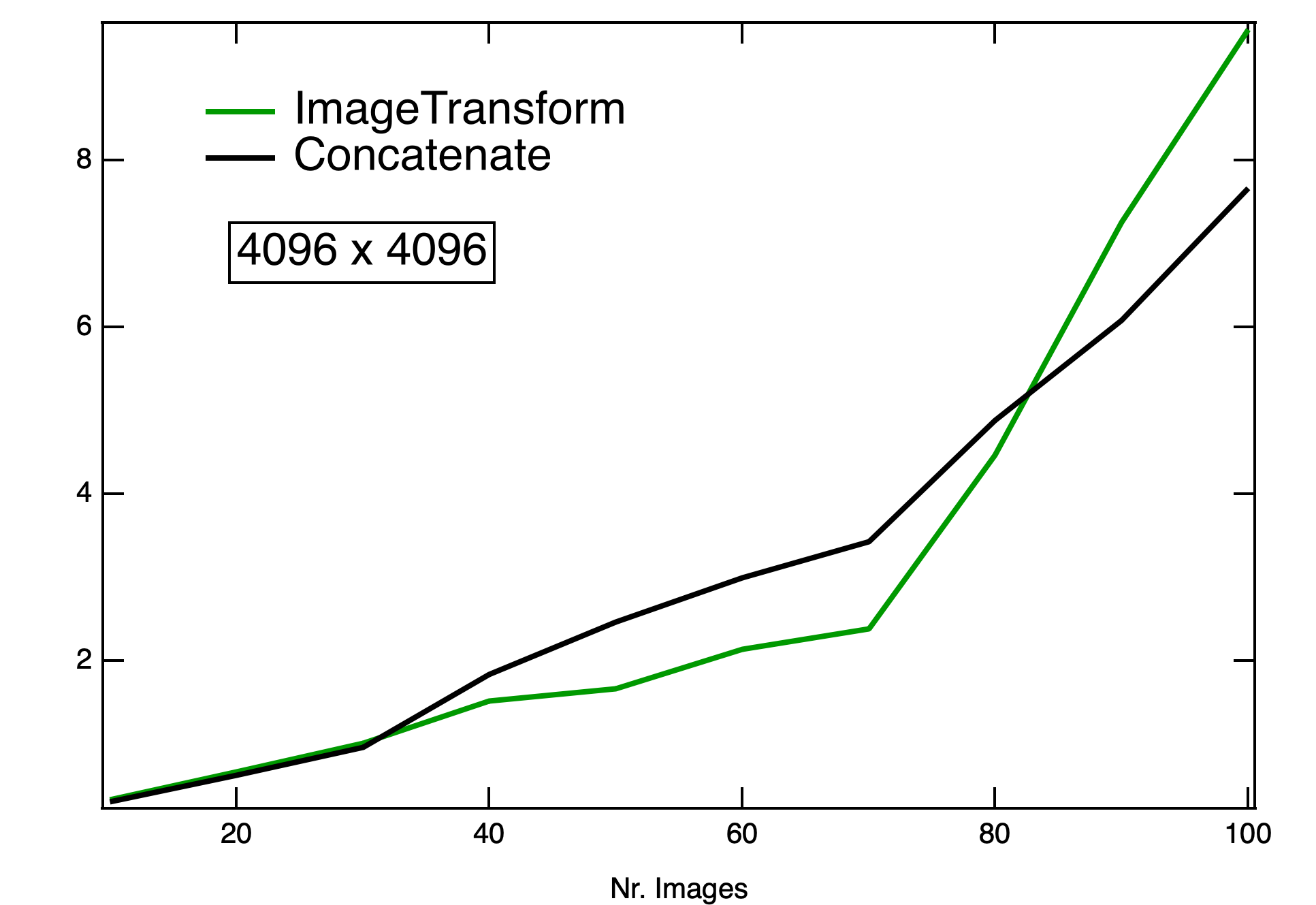
You can see the comparison between ImageTransform and Concatenation in the graphs (green and black line, respectively). I found most interesting the comparison between times depending whether the destination wave is already present.
Concatenation seems to perform the same (or worse!) when the destination wave is already there (haven't test the effect of the absence of flag /O).
On the other hand, ImageTransform stackImages has considerable gain for images of size (512 x 512) and is faster most of the times for (4096 x 4096) images. Strangely enough I see a reversal of this trend when I try to stack 50-80 images.
Are these results expected or I miss something here?
Cheers,
My system
MacBookPro 2020 - 2,3 GHz Quad-Core Intel Core i7, 16 GB 3733 MHz LPDDR4X.
IGORVERS:9.03
BUILD:40067
IGORKIND:pro64
FREEMEM:1130721280
PHYSMEM:17179869184
USEDPHYSMEM:488624128
NSCREENS:2
SCREEN1:DEPTH=32,RECT=0,0,2560,1440
SCREEN2:DEPTH=32,RECT=2560,70,4000,970
OS:macOS
OSVERSION:13.4.1
LOCALE:US
IGORFILEVERSION:9.03B01
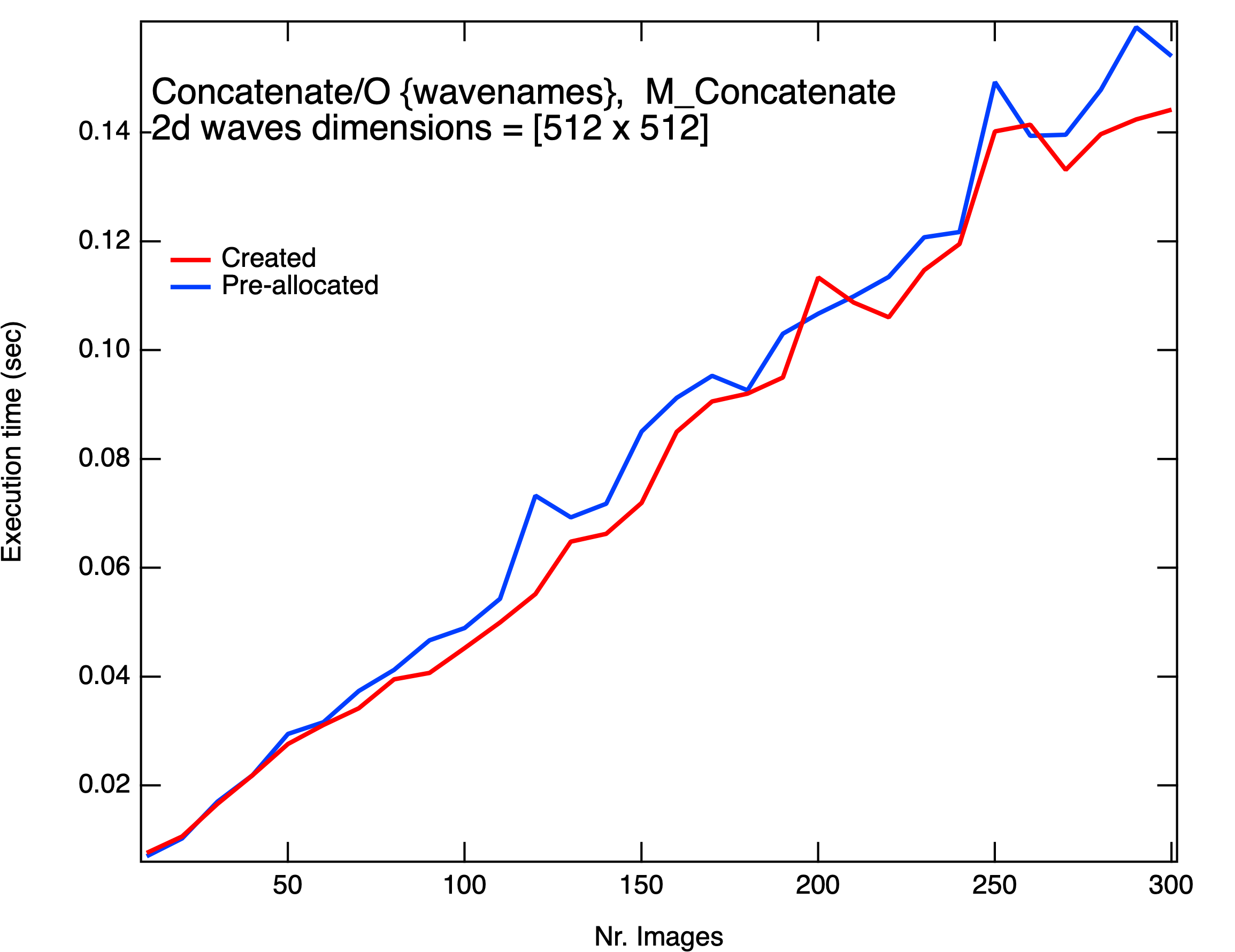
The fact that your Concatenate "pre-allocated" case is slower than your "Created" case is due to you assuming that Concatenate/O works differently than it does.
I think you are assuming that if the output wave already exists and is the correct size, memory doesn't need to be reallocated and therefore the operation should complete faster. That's not a crazy assumption, but it's wrong. Surprisingly, the actual behavior is even documented in the Details section of the Concatenate topic:
Perhaps "destWave is created..." should be changed to "destWave is [re]created..." to make it slightly more clear what is happening.
ImageTransform stackImages works differently in the case when the output wave already exists. It calls an internal command to make the output wave of the correct size and type, but if the output wave already exists and is already the correct size and type this is almost a no-op.
Your findings with the ~100 layer large images are also explainable. A 4096x4096x100 image of single precision floating point type is about 6.7 GB. That's just for the output, and you have the same number of bytes in your input waves. So that's over 13 GB of memory needed. According to your system info you have 16 GB RAM, so you're likely getting into the need for virtual memory somewhere around 75 layers.
On my machine (Windows 11, Intel 12900KS processor, 64GB RAM), I'm getting times that are close to 10x faster than yours. But I'm also seeing that the "Clean" case of ImageTransform is slower than the "clean" Concatenate case (tested only with 20 and 100 layers). I think your last graph shows the "clean" case of both operations, and if so you don't see quite the same thing. Looking at the code that executes it makes sense that ImageTransform would be slower in the "clean" case, but the explanation is getting into the weeds and some of the difference might be due to how memory allocation works on macOS vs. Windows.
June 29, 2023 at 09:19 am - Permalink