Brief performance review of key-value store methods in Igor Pro






Brief performance review of key-value store
Braun T., Huth M.
byte physics
Choosing suitable data structures to store data in a program is important for performance and maintenance. One common way is to store data on a key-value basis. The idea is to store data like a dictionary where a key value identifies the data record 1).
We show in this article a performance review of several approaches to store data on a key-value basis in Igor Pro. In the first section different methods are introduced that were benchmarked. Then the benchmark procedure is described and the results are discussed. At the end the experiment file with the benchmark routine can be downloaded.
Key-Value Store Methods
Wave
The simplest approach is to use a wave, where the wave name is the key. For each key a single element wave is created with the stored data in this element:
Writing: Make/T/N=1 dfr:$key/WAVE=wv wv[0] = dataStr
Reading: WAVE/SDFR=dfr/T wv = $key dataStr = wv[0]
StringByKey
For retrieving key-value pairs in strings Igor Pro has an own function StringByKey:
Writing: str += key + ":" + dataStr + ";"
Reading: dataStr = StringByKey(key, str)
DimLabel
Another method is using a wave and setting the keys as dimension labels. The data can be retrieved by the %dimlabel notation from the wave.
Writing: SetdimLabel 0, index, $key, textWave textWave[index] = dataStr
Reading: dataStr = textWave[%$key]
TextWave
Similarly we can use a text wave to store the key and use the index position as value. Actual data could be indexed then from another wave.
Writing: textWave[index] = key
Reading: FindValue/TEXT=(key)/TXOP=4/UOFV textWave index = V_Value
JSON XOP
A more general approach is implemented by our free JSON XOP 2). It enables storing and retrieving data from a JavaScript Object Notation entity. JSON is a data interchange format that uses key-value pairs to store data and has a human readable text representation 3).
Reading: JSON_SetString(jsonID, "/" + key, dataStr)
Writing: dataStr = JSON_GetString(jsonID, "/" + key)
Also noted should be that Igor Pro includes a SQL XOP to access SQL databases that in principle can store data by key-value pairs as well. It is not covered in this performance review as it not only requires to activate the XOP but a fully setup SQL server to connect to as well.
Benchmark procedure
For each method a key-value dataset is created by writing a number of key-value pairs to the data structure that the method uses. For benchmarking data retrieval, values are read back with an initial set of random ordered keys. To get good statistics on execution times a full dataset write/read cycle is repeated 10,000 times for dataset sizes up to 316 elements, 1000 times for dataset sizes up to 10,000 elements and 100 times for dataset sizes up to 1,000,000 elements.
Results
Discussion
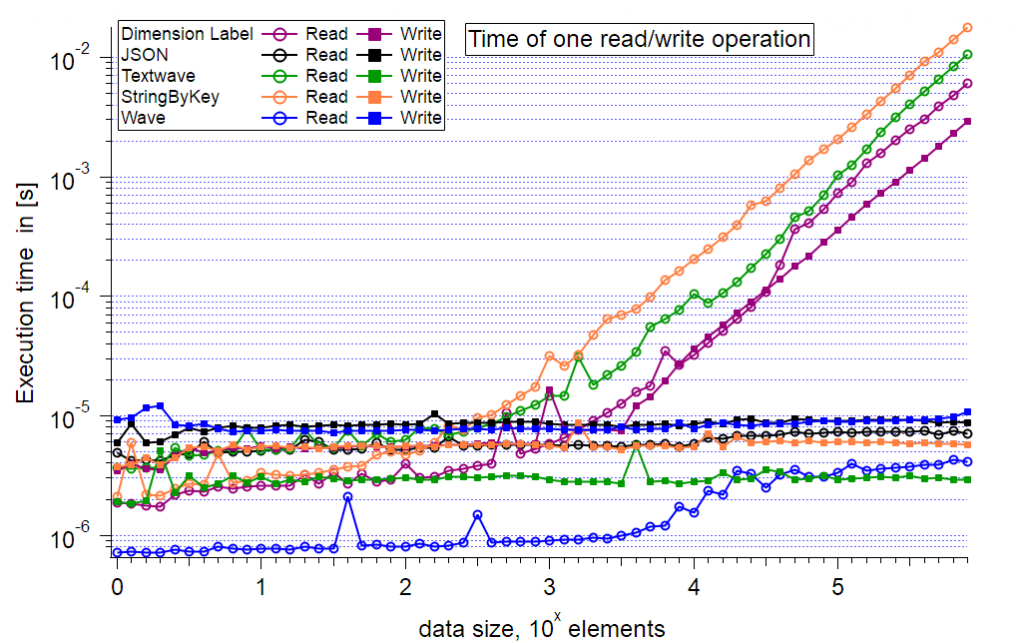
The first graph shows the execution time per read/write cycle versus the dataset size up to a size of 1,000,000 elements. The execution time is plotted using logarithmic scale. The curves indicate that the following operations show exponential performance decrease:
- Reading by Dimension Label
- Writing by Dimension Label
- Reading by Text Wave
- Reading by StringByKey
The onset where these methods get considerably slower than the other methods is at around 550 (~10^2.75) elements.
The only method that shows linear performance for reading and writing is the JSON method. For dataset sizes >6300 elements reading from a wave (blue circles) also shows an exponential performance decrease with a small slope.
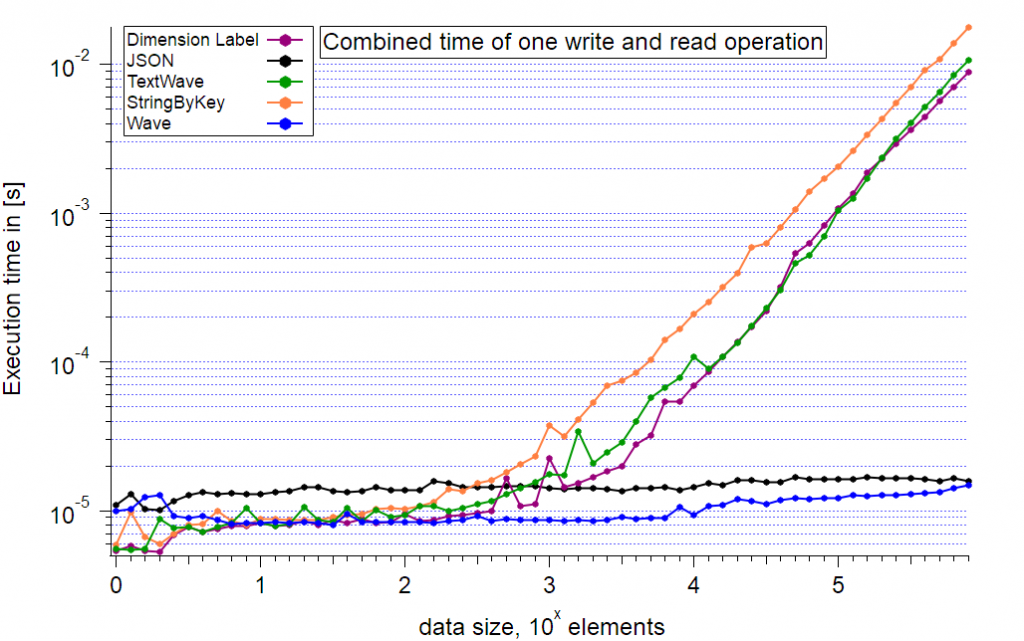
The second graph shows the summed execution times from reading and writing and better reflects a generic use case. Up to a size of ~300 elements the Wave, StringByKey, Dimension Label and TextWave methods are the fastest. Increasing the dataset size to up to 10,000 key-value pairs the fastest method is storing each value in an own wave. However, working with tens of thousands of waves can create other problems such as experiencing a performance penalty when working with other data in the same data folder. Also if the key is not a valid object name for Igor Pro, additional code for e.g. calculating a hash value has to be executed. The free JSON XOP is then a viable alternative that matches for larger datasets the performance of resolving waves by key. The exponential increase of the wave method for larger datasets indicates that the wave method will have a strong performance decrease for increasingly larger data sets.
Appendix
Here is the experiment with the benchmark routine: Experiment File
The results were obtained on a system with AMD Threadripper 1950X 3.4 GHz, 64 GB DDR4-2400 RAM, Windows 10 Pro, Igor Pro 8 Build 36002.
Note on error bars: In a simple approximation the errors scale with sqrt(times_run) if the timing distribution can be assumed gaussian. For obvious reasons, such as there is a minimum execution time limit the actual timing distribution is different. Considering that the measuring routine gets interrupted on a regular basis by the operating system only the results starting from a data size of 10 and larger have reasonably small confidence intervals. Some data points that show a characteristic increase for a specific data size proved to be reproducible on consecutive benchmark runs and could be related to properties of the benchmark system, e.g. caches. For larger dataset sizes the confidence interval is sufficently small to have no influence on the overall curve characteristic.
Interesting experiment.
FWIW, there is no point in using /UOFV with FindValue as that flag is ignored when searching a text wave.
Using individual waves as the key:value store, while surprisingly performant, is a pretty bad idea memory wise. A wave's header (in 64-bit Igor) is 648 bytes. So each wave will require 648 bytes + the size of the data. That gets to be a lot, particularly if you're in the range of 10,000 key:value pairs.
Is the JSON XOP using a hash table for its key:value store? You can write relatively simple code in Igor that uses StringCRC to construct a hash table. Using FindValue to find the CRC of your target string is substantially faster than using it to find some specific text.
December 7, 2020 at 05:21 pm - Permalink
> FWIW, there is no point in using /UOFV with FindValue as that flag is ignored when searching a text wave.
Thanks, looks like I missed that.
> Is the JSON XOP using a hash table for its key:value store? You can write relatively simple code in Igor that uses StringCRC to construct a hash table. Using FindValue to find the CRC of your target string is substantially faster than using it to find some specific text.
The underlying implementation in the JSON XOP is a std::map. I'd like to move that to std::unordered_map, but that is not so straightforward.
The idea with StringCRC is a good one. I'd love to have a pure IP implementation of a hash map with amortized constant time lookup.
December 8, 2020 at 08:09 am - Permalink
Here is a modified version of your experiment. I've broken out the different test methods so they are controlled by #defines and dropped the number of trials so that the tests run much faster.
I've also added a new method that is implemented by creating a crc32 based hash table.
If you could assume that two different keys would never have the same crc32, then this approach gives constant write time and nearly constant read time (with a significant step at about 3400 elements in my tests). In the attached experiment, this was created with the FindValue command in FindPointIndexOfString that uses /UOFV.
But realistically, you should not assume that two different keys will never give the same crc32 (unless you are actually checking that at insert time, for example). So you should use the FindValue command with the /S flag in the attached experiment. This gives these results:
For a large number of elements, using the hash table for lookup is substantially faster, though the performance is roughly linear, not constant.
One could conceivably make this a lot more complicated (but with closer to constant complexity) by using a better hash (eg. a 4 column unsigned int32 wave to store the 128 bits of an MD5 hash (Igor's hash function with mode 3). You would probably be safe assuming that no two inputs give the same md5 hash. Yes, it *could* happen, but pretty unlikely.
December 8, 2020 at 09:55 am - Permalink
Thanks for your input Adam. You don't need a better hash function. You just need a better way of distributing your data into the buckets and then compare the keys and not the hashes. I'm still struggling to get it always faster than the JSON XOP.
December 9, 2020 at 03:27 pm - Permalink
A bit of late night musing:
1. I see minor improvements if I use flags=2 with CmpStr (binary comparison). If you are willing to allow your keys to be case sensitive, then you save a bit of time by skipping the internal conversion of the parameters to the same case.
2. In HM_AddEntry and HM_GetEntry, I think you can do a shortcut. If nextFreeRow == 1, you don't need to do the CmpStr. I didn't test if that has any measurable impact on performance, but I suspect it will.
3. The Make and Redimension calls in HM_AddEntry are likely the cause of the plateau in write time from about 10e2 to 10e5 elements. If you expect the # of elements to be > 10e2 you might as well preallocate the keys and values waves ahead of time, before you start the timer for testing write performance. Yeah, that's sort of cheating, but already you're not counting the execution time of HM_Create. You might as well cheat as much as possible :)
4. In HM_Create, I'm surprised you didn't MultiThread the wave assignment. Although it's possible that this would decrease performance due to the memory allocation in a thread needing to use mutexes when the OS allocates memory for the wave.
December 9, 2020 at 09:30 pm - Permalink
I've now implemented a hashmap with separate chaining in pure Igor Pro with comparable performance to the JSON XOP. See https://github.com/AllenInstitute/MIES/blob/main/Packages/MIES/MIES_Has….
March 28, 2026 at 09:35 am - Permalink